长列表渲染
为什么需要虚拟列表
在正式"吃席"讨论虚拟列表前,我们先上个"前菜"看看什么是长列表。
什么是长列表
在前端的业务开发中,经常会碰到列表项,如果列表项数量过多,一般则会采用分页的方式来处理,而分页的形式也有2种:
- 前后翻页
- 上下滚动
前后翻页一般多用于后台管理系统中;而在用户端为保证较好用户体验,会采用上下无限滚动的方式,我们一般把这种列表叫做长列表。
比如,常见的微博列表等
长列表的问题
目前看来无限滚动的长列表对用户来说体验是很好的,但是这里会有个问题,当用户滚动的屏数过多时,就会出现页面滑动卡顿、数据渲染较慢、白屏的问题,究其原因是列表项过多,渲染了大量dom节点。
为了解决上述问题,就引入了一种叫虚拟列表的解决方案。
虚拟列表的优势
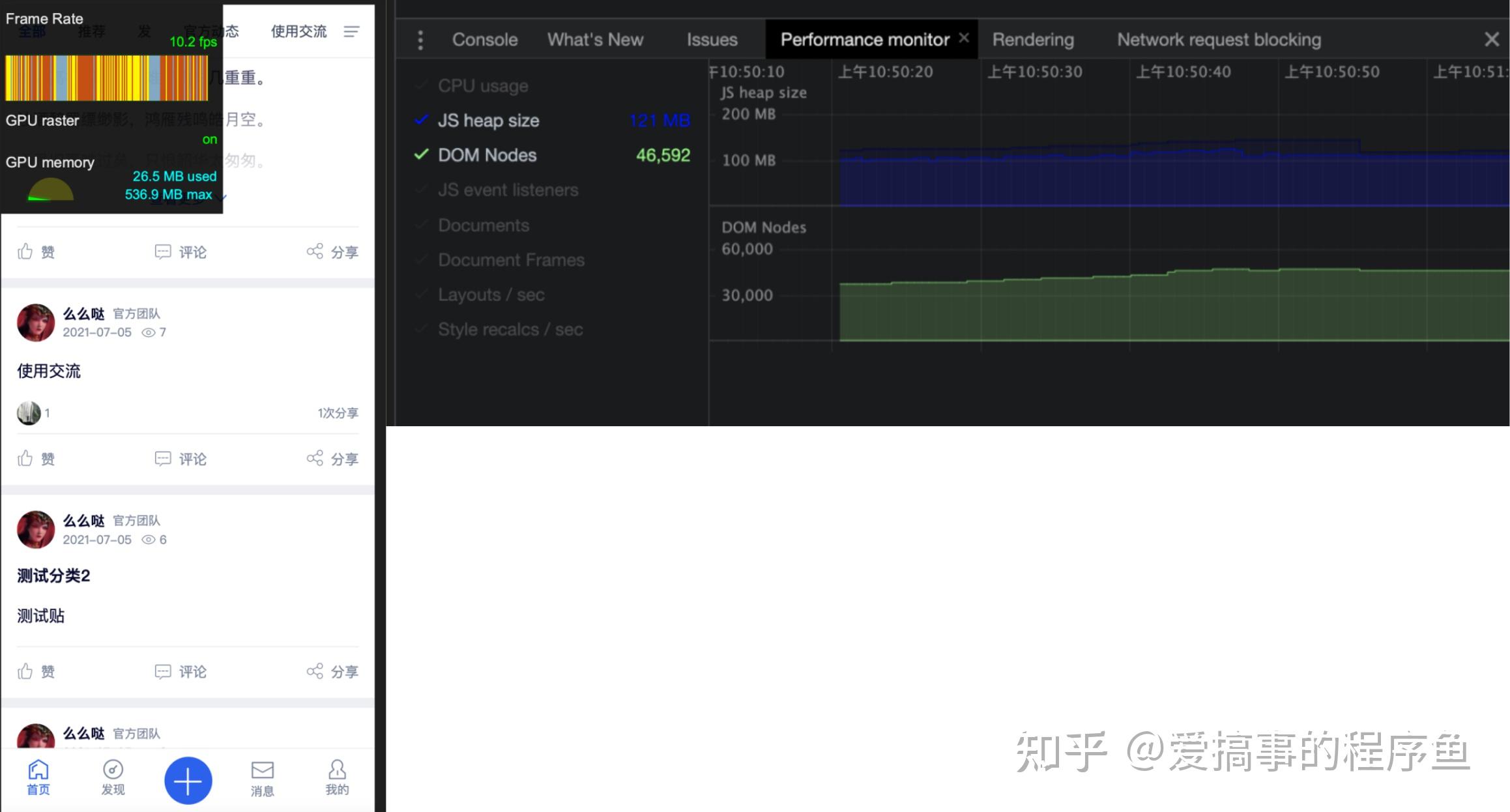
下面就通过两组图示数据来对比下,当滚动大约10+页时引入了虚拟列表前后的区别:
使用前
- FPS:10
- JS内存:121MB
- DOM节点数:46592
使用后
- FPS:40
- JS内存:102MB
- DOM节点数:24268
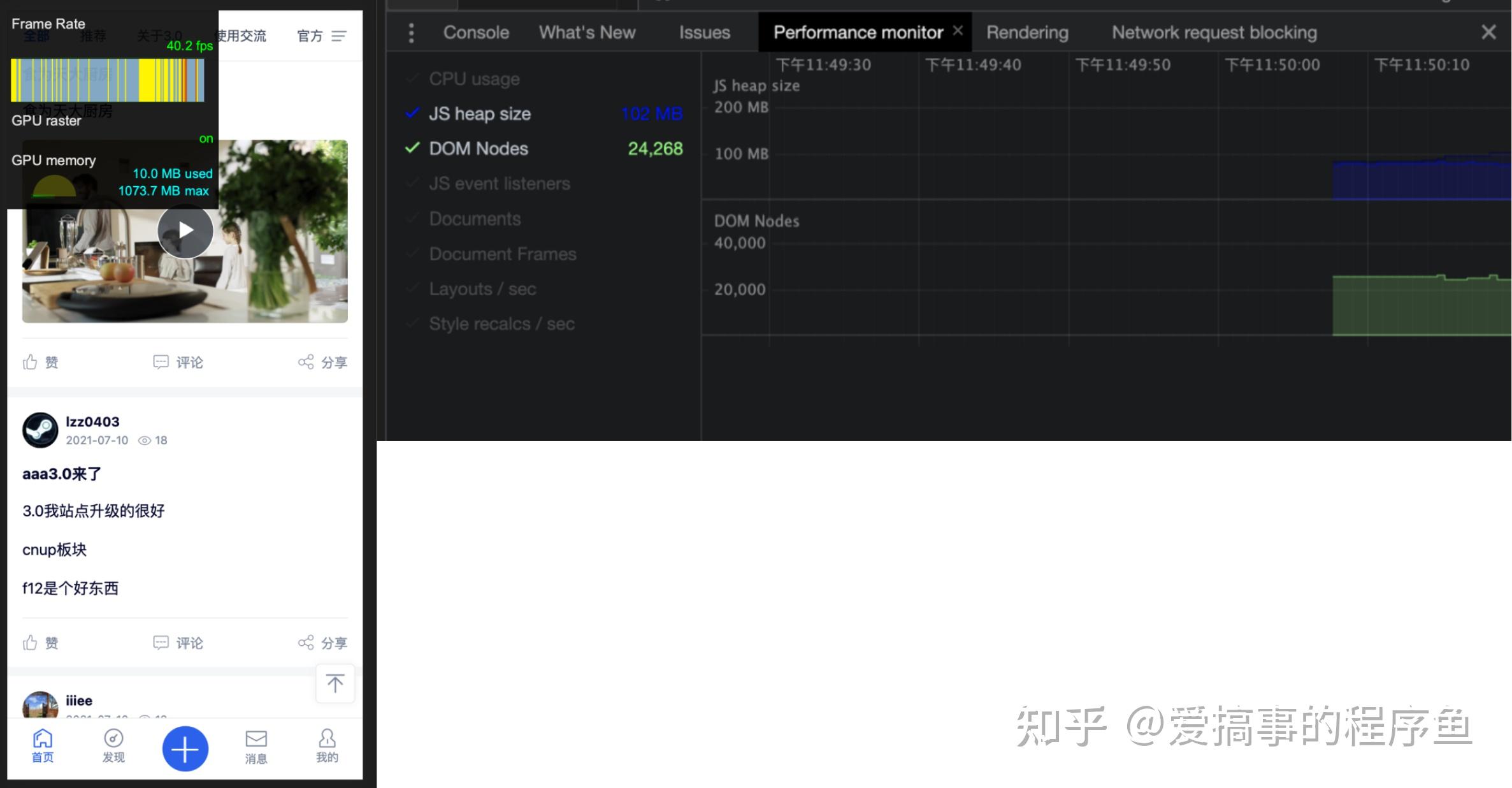
可以看到在引入虚拟列表后,在FPS、JS内存、DOM节点数各方面上都有较大程度的提升,而且随着滚动页数的持续增加,其效果会更加显著。
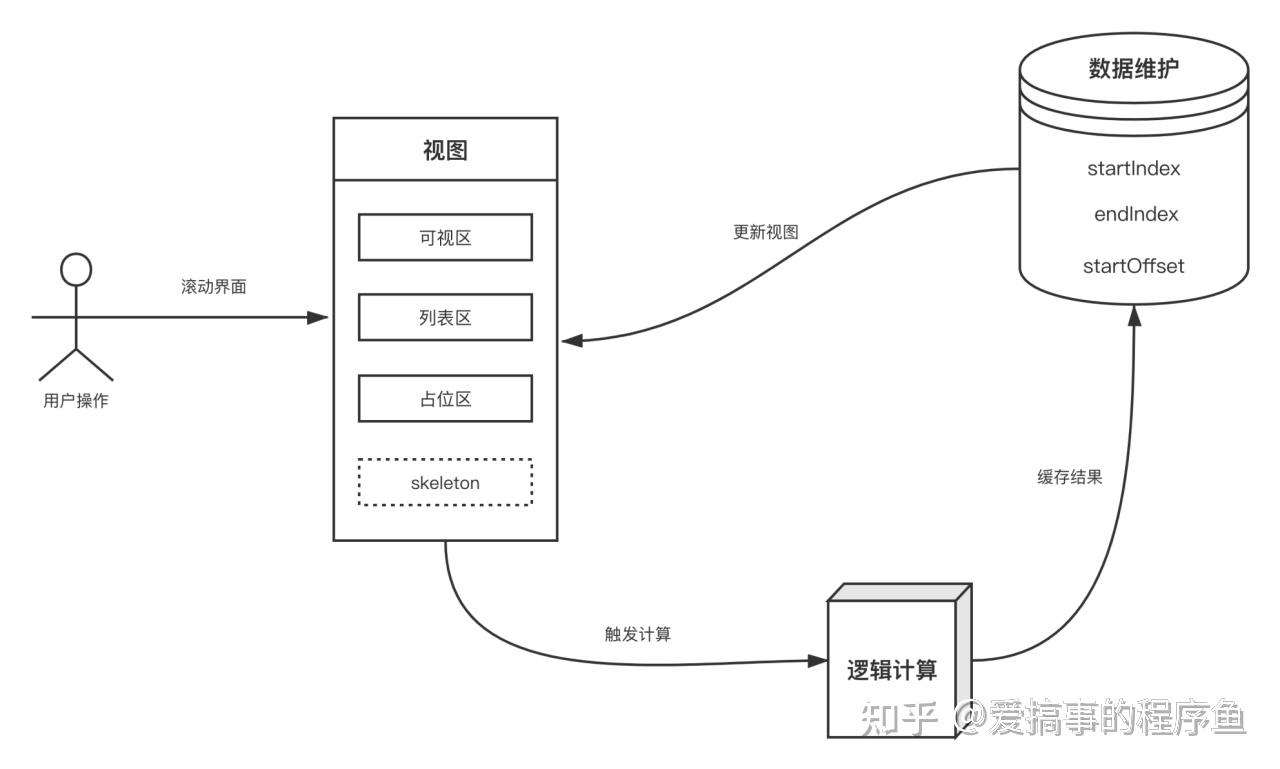
虚拟列表的原理
只对可见区域进行渲染,对非可见区域中的数据不渲染或部分渲染的技术,从而达到极高的渲染性能,虚拟列表其实是按需显示的一种实现。
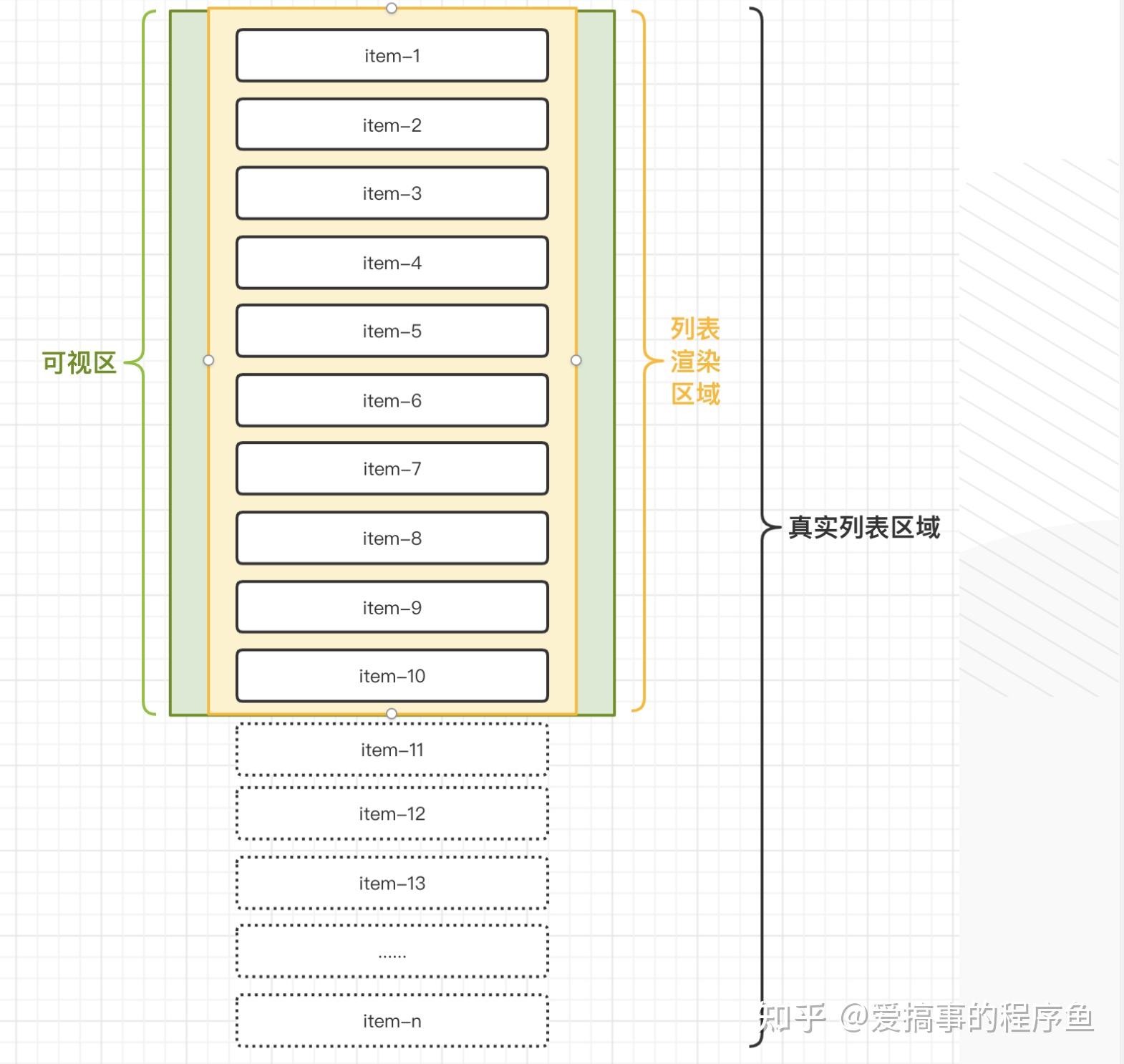
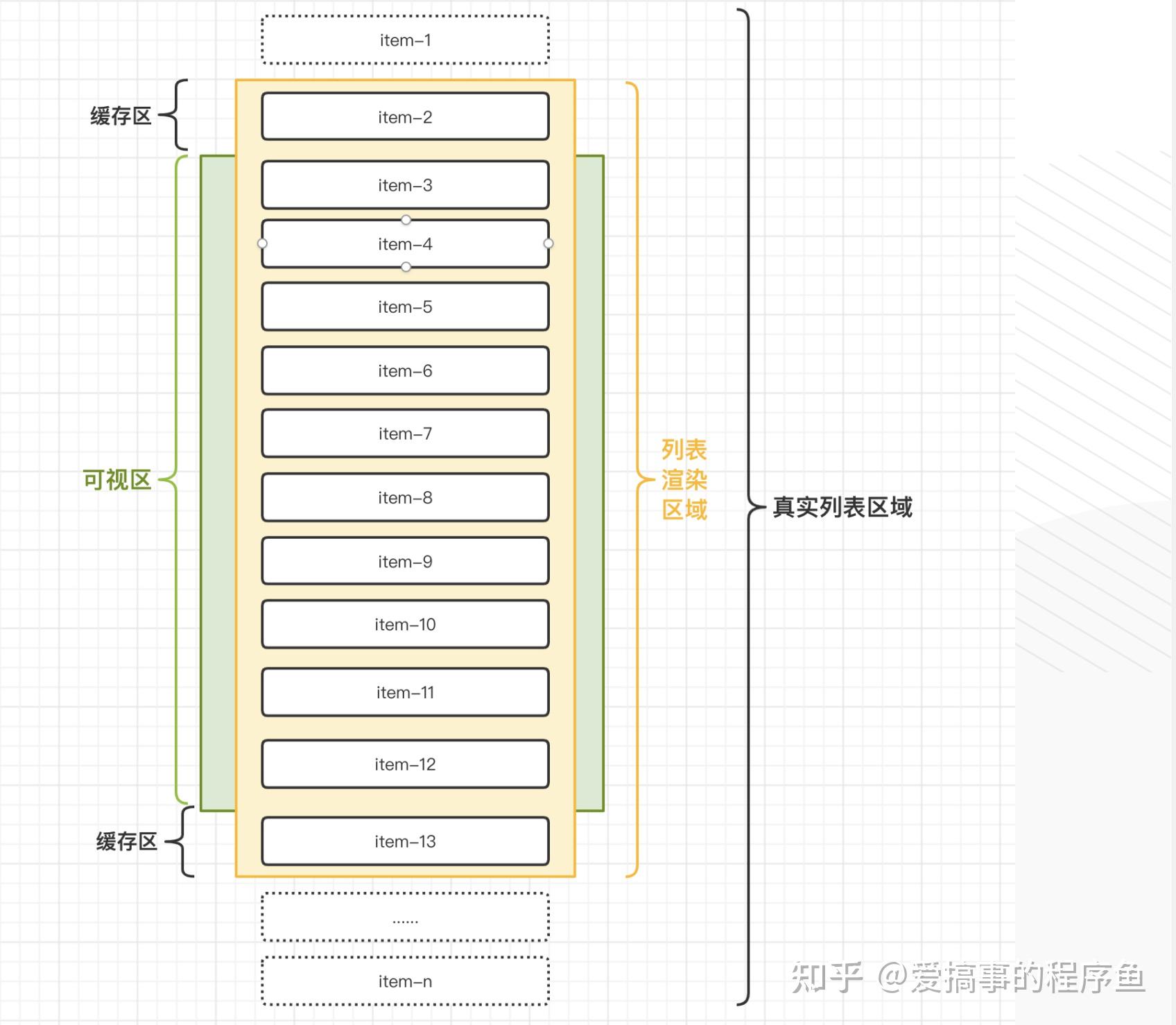
如图示例,其组成一般包含3部分:
1. **可视区:**滚动容器元素的视觉可见区域。
2. **列表渲染区:**真实渲染列表元素的区域,列表渲染区大于等于可视区。
3. **真实列表区:**又叫可滚动区,滚动容器元素的内部内容区域。
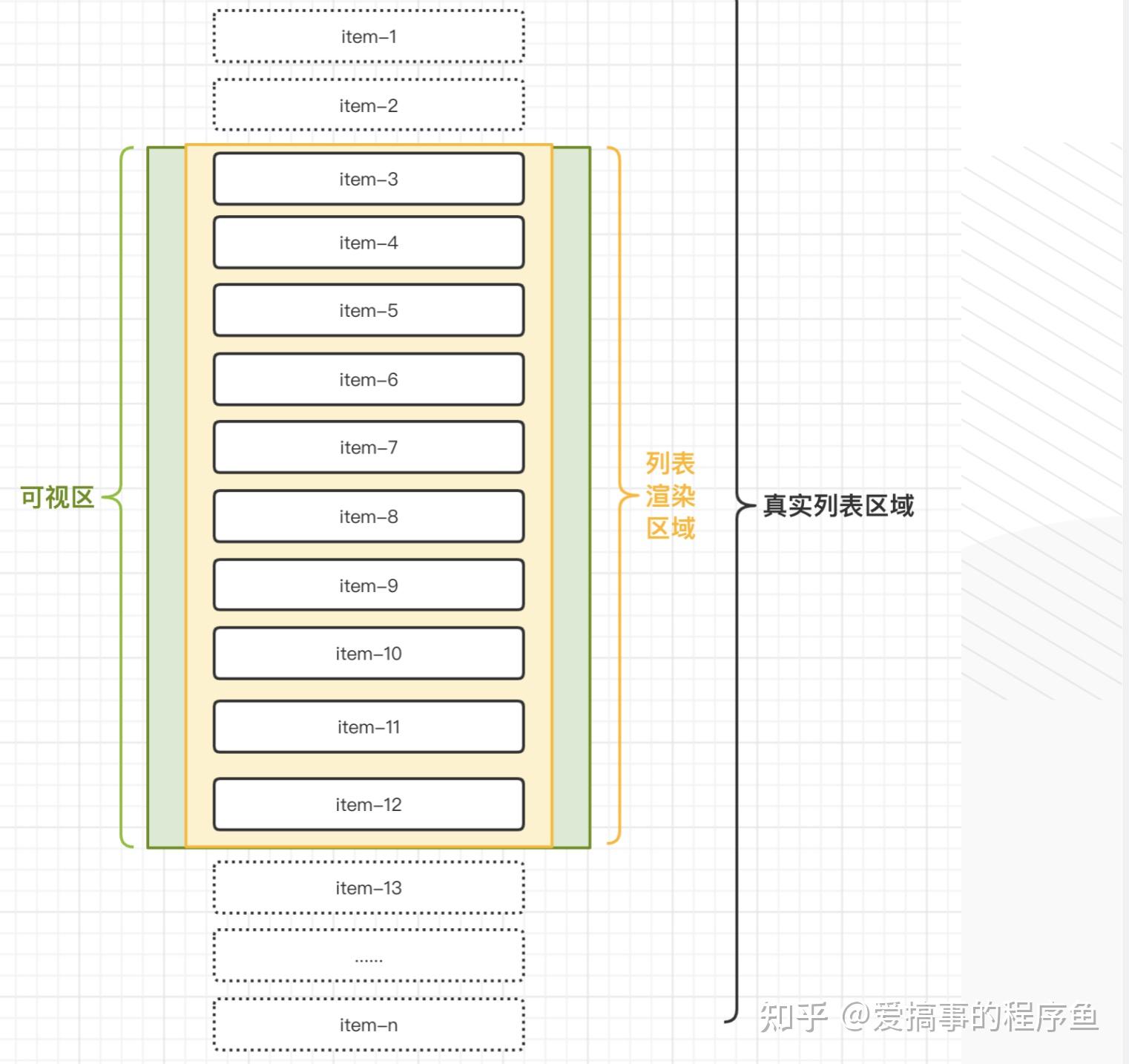
当用户操作滚动列表后:
1. 显示可视区中的元素(item3~item12)
2. 隐藏可视区外中的元素(item3和item12之外的)
虚拟列表的实现
"君子动手不动口",说了这么多,下面我们就来实操下具体如何实现一个虚拟列表,本文是以React为例。
视图结构
按照图示,我们先构造如下的视图结构
1. **viewport:**可视区域的容器
- **list-phantom:**容器内的占位,高度为真实列表区域的高度,用于形成滚动条
3. **list-area:**列表项的渲染区域
<div className="viewport">
<div className="list-phantom"></div>
<div className="list-area">
<!-- item-1 -->
<!-- item-2 -->
<!-- item-n -->
</div>
</div>基本思路
从虚拟列表的原理中可以知道,其核心思路是处理用户滚动时可视区元素的显示和可视区外元素的隐藏,这里为了方便说明,引入以下相关变量:
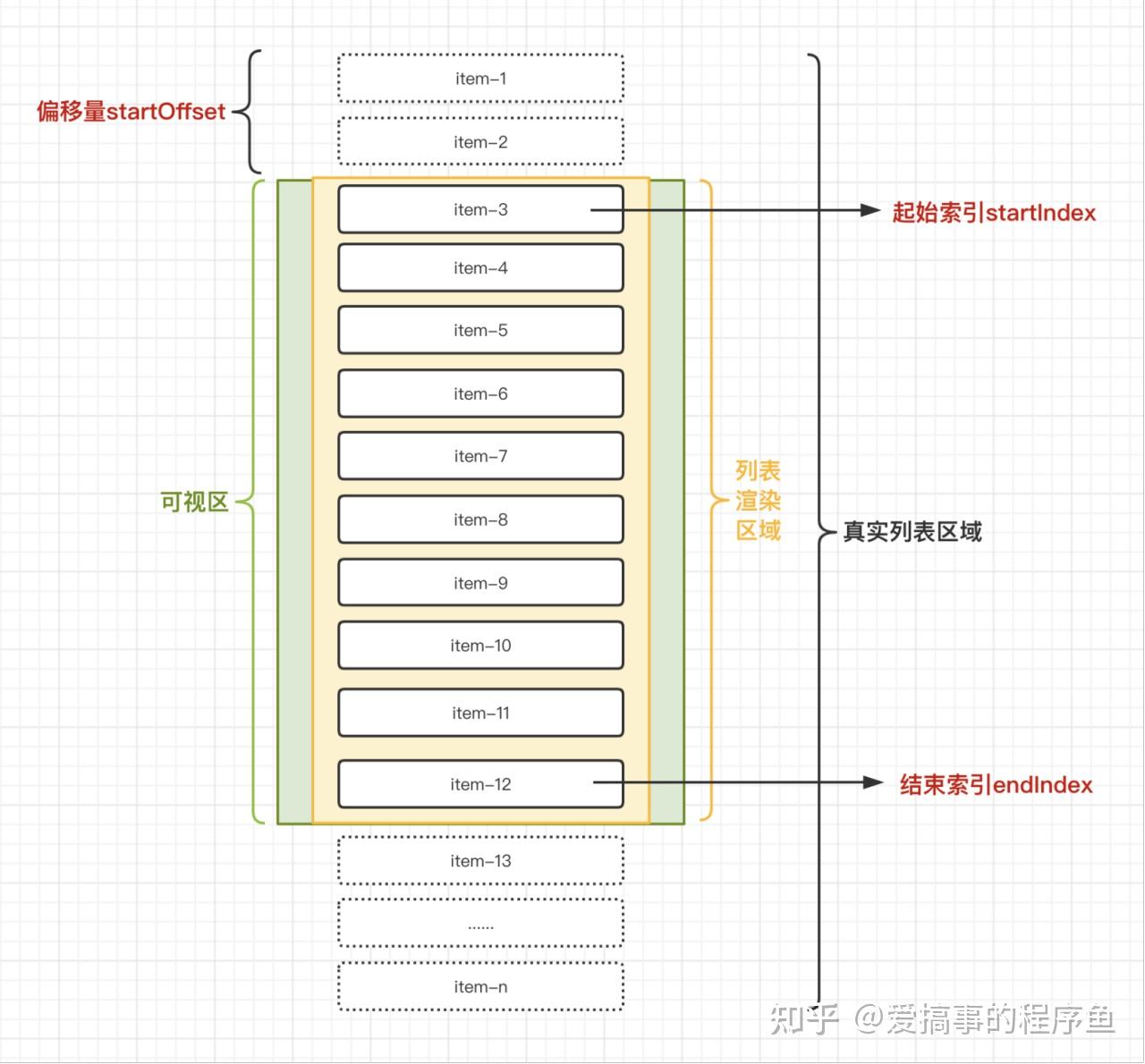
1. startIndex:可视区第一个元素标号(图示中为3)
2. endIndex:可视区最后一个元素标号(图示中为12)
3. startOffset:可视区第一个元素的向上偏移量
当用户滚动列表时:
1. 计算可视区的 startIndex 和 endIndex
2. 根据 startIndex 和 endIndex 渲染数据
3. 计算 startOffset 偏移量并设置到列表渲染区
事件处理
这里我们先假定列表项的高度固定为100px,则我们可设置和推导出:
1. 列表项高度 itemSize = 100
2. 可视区可显示数量 viewcount = viewport / itemSize
3. 可视区最后一个元素标号 endIndex = startIndex + viewcount
当用户滚动时,逻辑处理如下:
1. 获取可视区滚动距离 scrollTop;
2. 根据 scrollTop 和 itemSize 计算出 startIndex 和 endIndex;
// 获取startIndex
const getStartIndex = (scrollTop) => {
return Math.floor(scrollTop / itemSize); // 这里可以思考下,为什么要用Math.floor
};3. 根据 startIndex 和 itemSize 计算出 startOffset;
4. 只显示startIndex 和 endIndex之间的元素;
5. 设置 list-area 的偏移量为 startOffset;
其中第2步是比较关键的(后面也会多次提到),其实计算出了startIndex 也就计算出了endIndex 和 startOffset;
实现效果
最终的效果如下,具体代码实现可查看在线示例。
动态高度
"理想很丰满,现实很骨感",实际上在业务开发中,基本很少碰到高度项列表固定的情况,大部分是文本、图片、富文本等不定的高度,对于这类不定的高度那我们该如何处理呢?
动态高度的类型
对于这类不定的高度,我们一般可以分为两种类型:
1. 逻辑动态高度
2. 动态高度(由渲染内容决定高度)比如,文本、图片、富文本。
以上两种类型都可以在内容渲染完成后,获得其高度;但是不同的是 逻辑动态高度 也可以在渲染前通过业务数据计算得出,本质上也可以理解为固定高度,只是获取方式复杂了些;而类型2中的只能在内容渲染完成后才可以获取。以下动态高度的讨论都是指类型2。
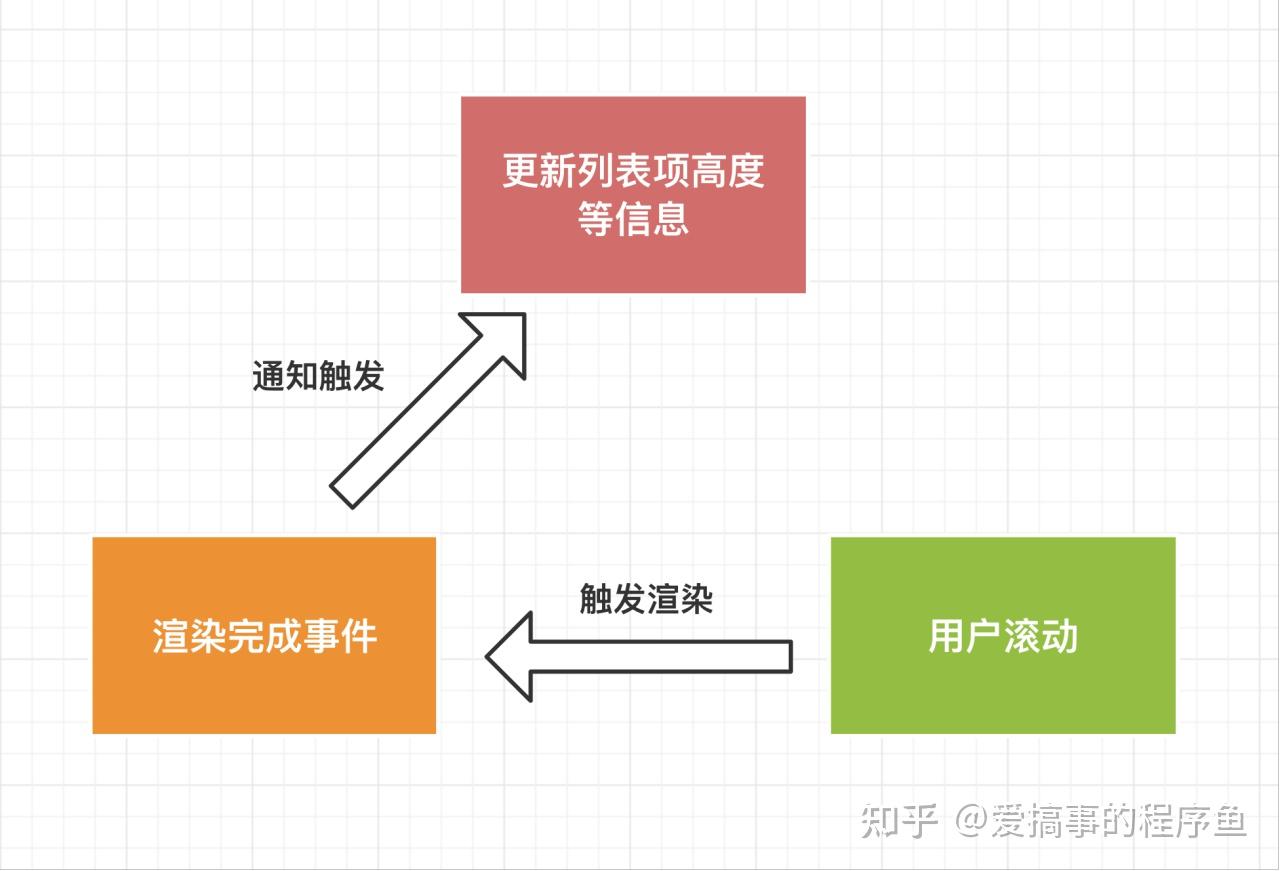
事件通知
这里我们也比较容易想到,当渲染完成后,我们获取到列表项的高度信息,然后再更新指定列表项的高度。
具体实现
构造记录列表项位置信息 position 的数组 positions:
1. top: 当前项顶部到列表顶部的距离
2. height: 当前项的高度
3. bottom: 当前项底部到列表顶部的距离
4. index: 当前项的标识
那么计算startIndex的逻辑则变为:
// 获取startIndex
const getStartIndex = (scrollTop) => {
let item = positions.find((i) => i && i.bottom > scrollTop);
return item.index;
};当有item项高度变化后,我们只需要维护这一份 positions 数据即可,从而大大减少了处理起来的复杂度。
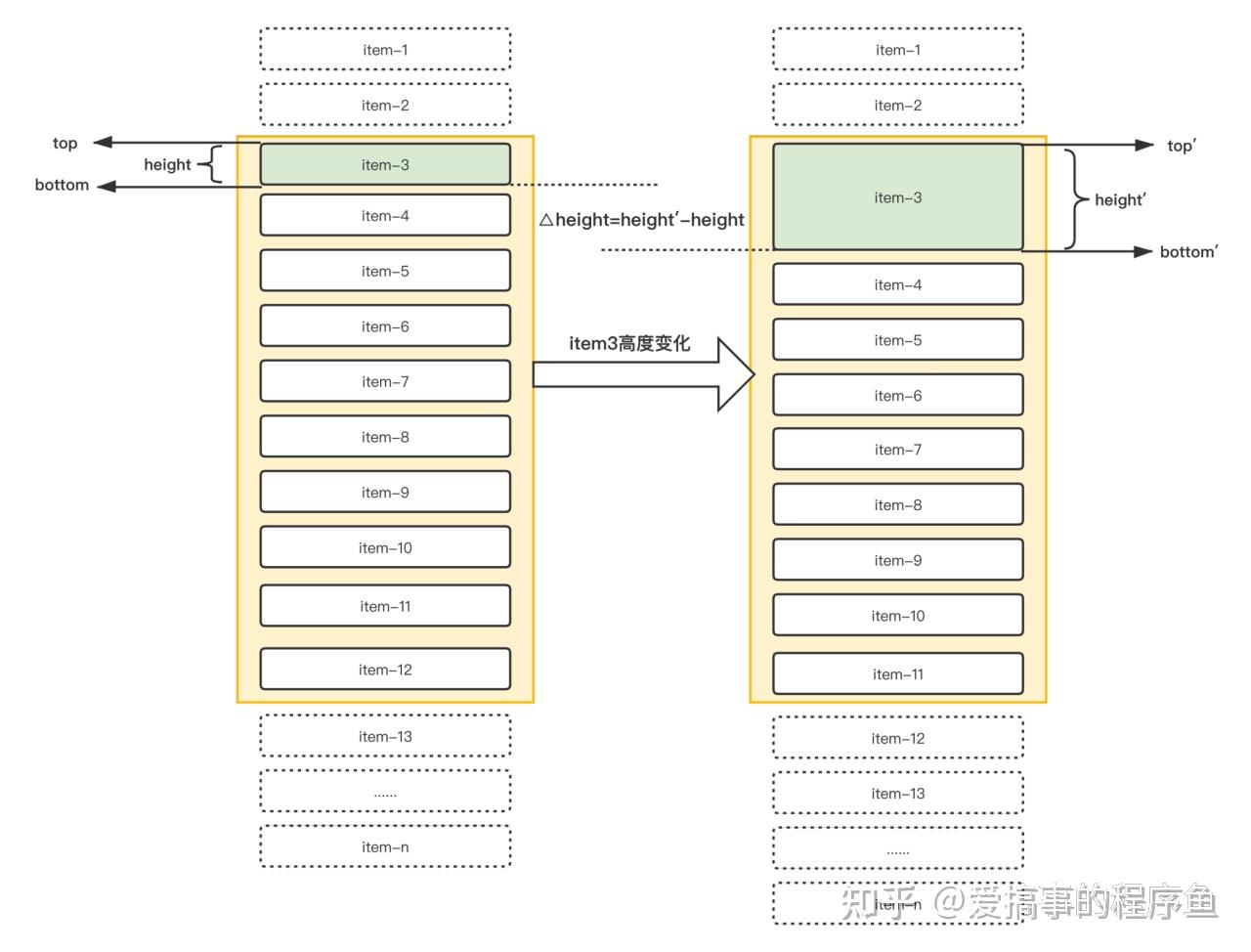
那么我们以 item-3 项为例,来具体看下当其高度变化后的具体影响
// 高度变化前position信息
{
index: 3, // 当前列表项的标识
height: defaultItemSize, // 当前列表项高度(默认初始高度)
top: index * defaultItemSize, // 当前项顶部到列表顶部的距离
bottom: (index + 1) * defaultItemSize, //当前项底部到列表顶部的距离
}
// 高度变化后,设变化的高度dHeight = newHeight - oldHeight
{
index: 3, // 当前列表项的标识
height: defaultItemSize + dHeight, // 当前列表项高度
top: index * defaultItemSize, //当前项顶部到列表顶部的距离
bottom: (index + 1) * defaultItemSize + dHeight, //当前项底部到列表顶部的距离
}可以看到当item-3变化后,只有height和bottom发送了变化,top并未发生变化,不过这里需要注意,还需要更新item-4~n的信息,即向下更新相关项的位置信息。
具体代码实现,可查看在线示例。
主动监听
那事件绑定会有什么问题呢?
当业务足够复杂时,会有大量操作触发高度更新,会导致有大量的绑定事件,从而对性能造成影响;也有可能遗漏绑定相关的事件,导致高度不更新,影响用户体验。
所以看来,事件通知的方式不管是对性能还是用户体验都是不太理想的。下面介绍另一种实现方式。
ResizeObserver API
我们先看看MDN的介绍

简单来说,ResizeObserver可以监听到指定元素的高度的变化,而且是原生浏览器层面的支持,性能方面也是可靠的。
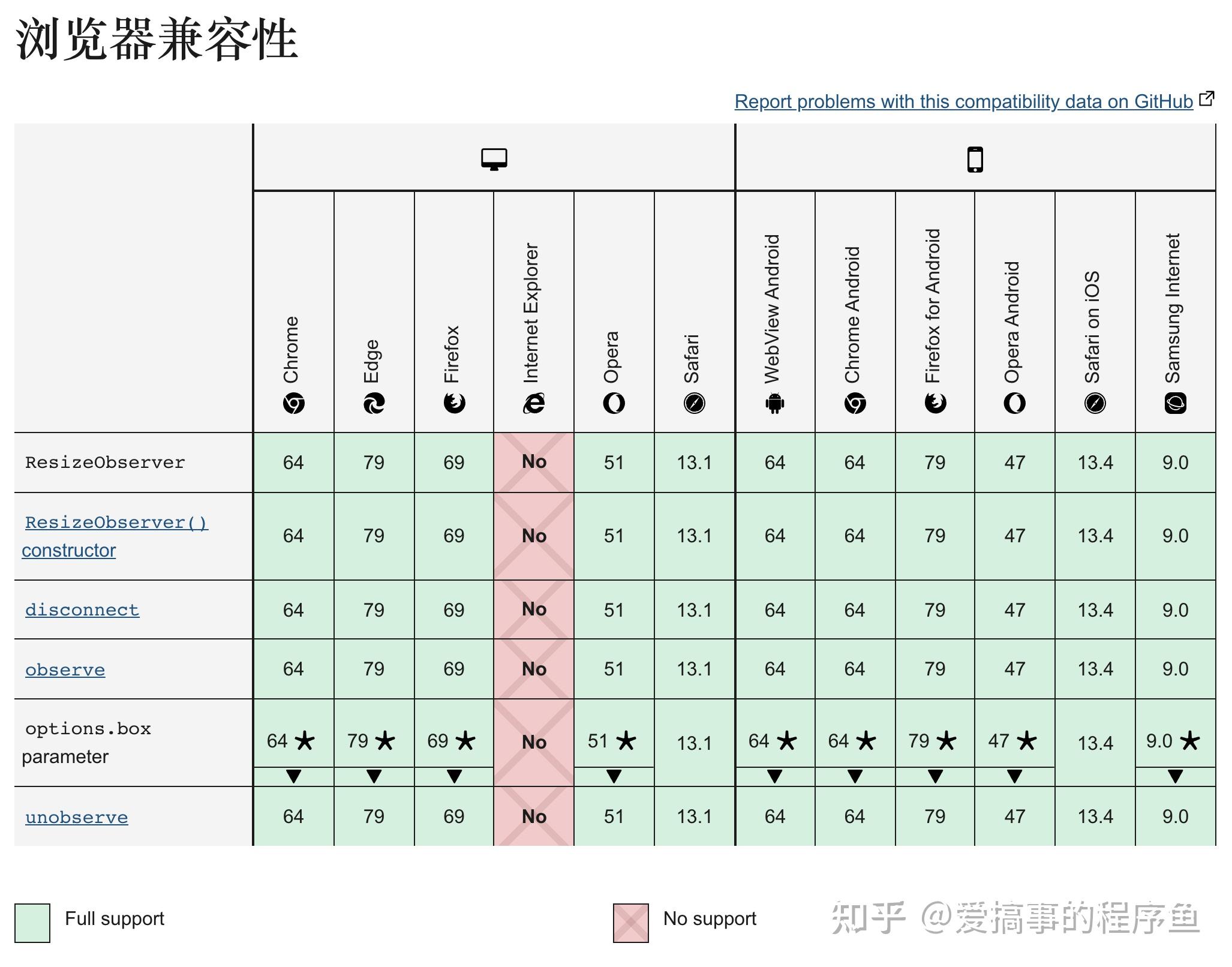
兼容性方面,除了IE,其他也都是支持的:
关键代码实现:
// 监听高度变化
const observe = () => {
const resizeObserver = new ResizeObserver(() => {
// 获取当前列表项的高度
const el = element.current;
if (el && el.offsetHeight) {
// 触发高度更新
measure(index, el.offsetHeight);
}
});
resizeObserver.observe(element.current);
return () => resizeObserver.disconnect();
};实现效果
最终采用主动监听的效果如下,具体代码实现可查看在线示例。
探索优化
到此为止,我们就实现了一个支持动态高度虚拟列表,那是不是到这里就结束了呢,当然不是,在技术的研究上,我们要像我国的航天事业一样"弘扬探月精神,勇攀科技高峰",勇于探索,勇于创新。
这里的话,笔者总结出了下面2个问题,当然也不止这2个问题,大家也可以自己思考下。
1. 滚动过快出现会白屏
2. 滚动时有大量的计算
白屏优化
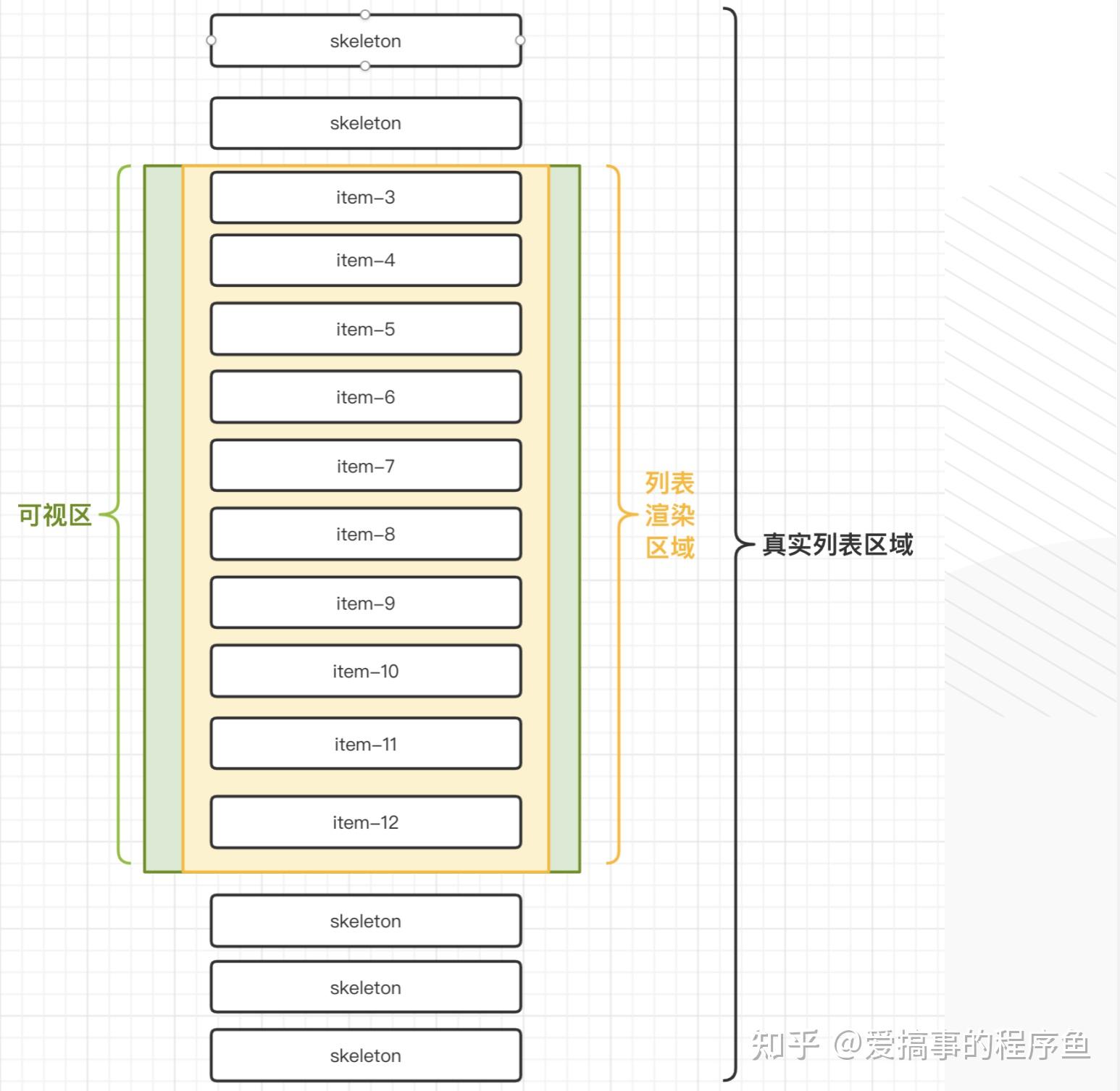
方案一:增加缓存区
在虚拟列表的原理中有提到过,**列表渲染区是可以大于等于可视区,**这里的采取措施就是列表渲染区域要大于可视区。
**措施:**在可视区外设置缓存区,额外渲染合适的列表项。
**优势:**在滚动过快时,会先显示缓存区中的元素,减少白屏出现的情况。
**不足:**缓存区域设置过大,也会导致渲染性能变差,需要结合具体的业务场景设置合适的缓存值。
方案二:部分渲染
在前面虚拟列表的原理中也有提到过,对非可见区域中的数据不渲染或部分渲染的技术,这里所用到的就是不可见列表项的部分渲染。
**措施:**采用skeleton加载骨架屏来代替原有的不渲染部分,这样当滚动过快时,白屏也就替换为了加载屏。
**优势:**用户体验上会有所增强。
**不足:**会额外渲染skeleton的dom元素。不过对比整个列表元素的dom节点来看,可以忽略不计的。
计算优化
首页我们来看下,上一节提到的 positions 数组其实是个标准的按照各项位置升序的有序数组。
而最重要的和调用次数最多的逻辑是计算startIndex:
// 获取startIndex
const getStartIndex = (scrollTop) => {
let item = positions.find((i) => i && i.bottom > scrollTop);
return item.index;
};所有,我们可以采用二分查找法来进行优化,具体二分查找法的实现就不在这里展开了,可查看在线示例。
const getStartIndex = (scrollTop) => {
// let item = positions.find((i) => i && i.bottom > scrollTop);
let item = binarySearch(positions, scrollTop);
return item.index;
};其时间复杂度也从O(n) 降为 O(logn);
实现效果
最终优化过的效果如下,具体代码实现可查看在线示例。
面向未来
多平台支持
下面是虚拟列表的通用模型 ,而对于其他平台如小程序、IOS、flutter等的实现,或者能不能抽象出一套通用架构,对于不同的平台只需在这套架构上实现特定平台的代码逻辑即可产出特定平台的虚拟列表,也是未来需要进一步探索研究的。